6月26日,科大訊飛語音合成技術全新升級,一句話聲音復刻與超擬人合成兩大核心能力實現突破。據專業測評顯示,科大訊飛一句話聲音復刻技術在相似度、準確度等維度行業領先。
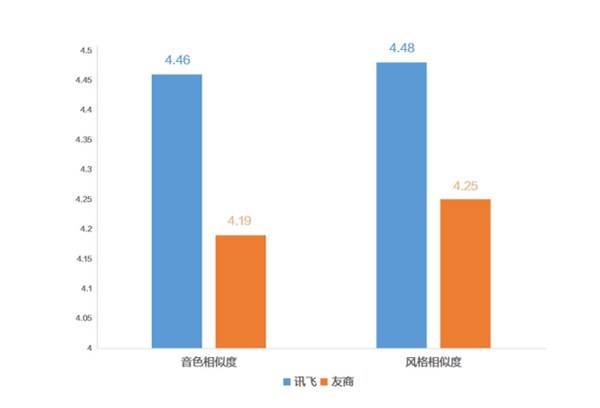
??訊飛星火APP的“一句話聲音復刻”功能自2024年4月上線以來,備受用戶和行業認可。在智能語音領域,聲音復刻效果的核心指標始終圍繞相似度與準確度兩大維度展開。相似度決定“第一耳印象”,包含音色特質及風格韻味;準確度則關乎聲音復刻是否好用,確保發音標準、停頓自然、語氣連貫。
??此次訊飛技術突破的關鍵,除了星火語音大模型底座的基礎和持續迭代,還構建了一套三階段層次化語音建模框架。首先,通過星火底座大模型精確捕捉發音規律和韻律特征。其次,在音色恢復階段解耦并重構聲學特征。最后,通過高精度聲碼器恢復高保真波形。
??這套語音建模框架突破了語義表征,采用mel?VQ-AE模型結合語音自監督預訓練編碼器,并引入音色最小互信息約束,成功解耦出音色無關的離散語義token。這種結構實現了發音內容與音色特征的可控分離,也顯著提升了語義LLM的建模穩定性。
??在音色解耦表征能力的基礎上,科大訊飛在聲音復刻場景針對性進行兩項關鍵技術的嘗試與突破:音色編碼增強——在聲學模型中創新性地融合全局聲紋嵌入與局部幀級音色編碼,提取細粒度音色特征,并構建聲紋空間語義一致性損失函數,顯著提升音色恢復的相似度。強化學習——通過語音魯棒性評價模型和人工標注構建偏好數據集,采用基于DPO的強化學習策略,大幅提升合成語音的穩定性和自然流暢度。只需一句話錄音,AI就能完整捕捉用戶喉腔共鳴、口音特點、氣息流轉等發音特征,精準還原用戶的停頓習慣、情感起伏和呼吸節奏,達到真人難以區分的復刻效果。
??從曾經要錄上數十個小時的語音素材,到錄入幾段話,再到現在僅用一句話就能復刻聲音,語音合成技術一直在向更快、更好、更易用的方向奔跑。一句話復刻技術的進階,代表著能用更少的資源、更快的速度帶來驚艷且實用的效果,顯著降低了應用門檻,在AI賦能千行百業的大背景下,讓更多的場景和行業衍生出更多的個性化需求,突破并得到實現。
??在需要深入交流的場景里,僅有相似音色并不足夠。訊飛的超擬人合成技術此次進階的重點是賦予AI聲音以“上下文情商”。面對多輪對話的復雜度,科大訊飛開發了上下文感知的語音生成系統。該系統融合歷史文本及對應音頻特征,通過跨模態編碼器分析上下文,讓AI聲音能像真人一般敏銳響應情緒轉變和話題轉換。在真人與AI聲音的對話測試中,隨著話題和情緒變化,合成聲音的語氣會實時調整,給出恰如其分的情感回應,整體自然度接近真人水平。
??AI語音技術落地最顯著的領域當屬智能汽車座艙。今年初,蔚來在“Banyan?榕?3.1.0版本”中為NOMI助手引入的超擬人情感音色,正源于訊飛的深度賦能。搭載該技術的蔚來新車型(如ET9、新ES6/EC6/ET5系列等),成為行業首款應用AI生成式語音合成框架的車型。除蔚來外,奇瑞、廣汽、長城、日產、本田等主流車企同樣選擇了訊飛超擬人技術,重塑車內智能交流體驗。
??訊飛語音技術的輻射范圍遠不止車載場景。在教育領域,星火大模型賦能的AI學習機已能像真人教師般開展多輪對話診斷學情,為學生定制個性化學習路徑。2025年暑期升級中,學習機新增的“AI?1對1互動式問診規劃”功能,通過幾輪對話即可分析知識掌握情況,結合學生能力層級生成精準學習方案。
??在數字內容創作領域,訊飛智作平臺的超擬人數字人技術實現“一張照片+一句話錄音”定制專屬虛擬人,其唇形同步率高達98%。該技術已幫助天津大學教師打造慕課個人IP,簡化教學視頻制作流程。醫療場景中,搭載情感合成技術的導診機器人使用方言與老年患者交流時,對話自然度提升200%。隨著星火語音大模型在教育、醫療、金融等領域的深度滲透,其技術底座已服務全國5萬余所學校、600家醫院及眾多金融機構。
??科大訊飛研究院院長劉聰表示:“我們希望聲音不止于工具,更成為承載情感與個性的新維度,賦能更多場景行業、催生更多可能。”屬于AI聲音的多元化、情感化時代,正加速駛入現實。


中安在線版權所有 未經允許 請勿復制或鏡像
增值電信業務經營許可證:皖B2-20080023 信息網絡傳播視聽節目許可證:1208228 2009-2010年度全省廣告發布誠信單位





